The much-anticipated Opus 4.7 was released today. It's the only 4.7 in the model family, with Sonnet and Haiku still at 4.6.
According to the claimed benchmarks, it shows a substantial jump in capability across the board, with notable improvements in:
- Visual reasoning — It can now "see" higher resolution pictures up to 2,576 pixels on the long edge, 3x more than Opus 4.6.
- Instruction following — It takes instructions more literally than the previous version. The called-out side effect is that users may need to re-tune any prompts and harnesses.
- Memory — It's better at using file-system-based memory, remembering important notes across long-running, multi-session work.
- Real-world work — Areas like financial analysis, legal, and professional slide presentations.
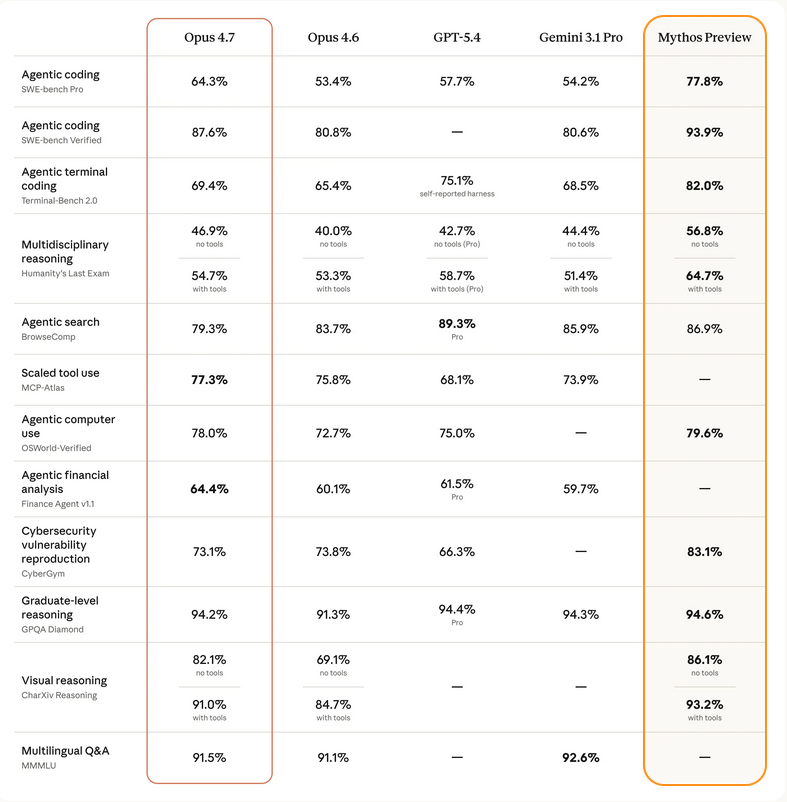
I like that they have also included benchmark numbers for the new unreleased Mythos Preview model. The jump in SWE-bench agentic coding from Opus 4.6 to Opus 4.7 is already substantial, and then there's a further leap to 93.9% for Mythos!
Interesting that the cybersecurity vulnerability reproduction score is actually slightly lower on 4.7 than it was on 4.6 — although it appears this may have been intentional.

We stated that we would keep Claude Mythos Preview's release limited and test new cyber safeguards on less capable models first. Opus 4.7 is the first such model: its cyber capabilities are not as advanced as those of Mythos Preview (indeed, during its training we experimented with efforts to differentially reduce these capabilities). We are releasing Opus 4.7 with safeguards that automatically detect and block requests that indicate prohibited or high-risk cybersecurity uses.
And...
Security professionals who wish to use Opus 4.7 for legitimate cybersecurity purposes (such as vulnerability research, penetration testing, and red-teaming) are invited to join our new Cyber Verification Program.
This seems to imply the model was intentionally dialled back to reduce the risk of misuse, with access to the full capabilities gated behind the new Cyber Verification Program.
Other Notable Changes
Along with the model, they are releasing these notable controls:
- New
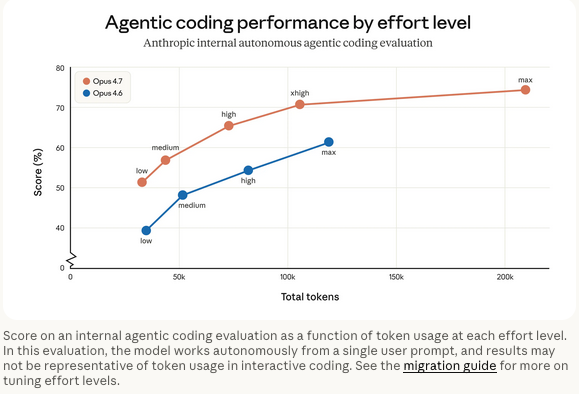
xhigh reasoning effort — an effort level between high and max, giving users finer control over the tradeoff between reasoning and latency on hard problems. In Claude Code, the default effort level has been raised to xhigh for all plans.
- New
/ultrareview slash command in Claude Code — produces a dedicated review session that reads through changes and flags bugs and design issues that a careful reviewer would catch.
Opus 4.7 does use more tokens, and it's easy to see why they introduced this new effort level. xhigh scores substantially higher than high at the cost of more tokens burned — but max uses double the tokens of xhigh for a smaller score jump than high to xhigh.